Programmiertechnik
Aus SELFHTML-Wiki
(Weitergeleitet von Programmiertechnik/Grundlagen und Konzepte)
Artikel, die sich mit den allgemeingültigen Aspekten von Programmierung beschäftigen.
- Einführung in die Programmierlogik
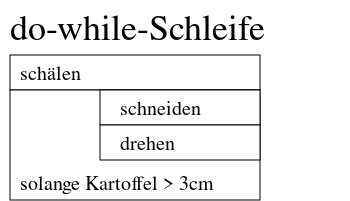
Abläufe in Algorithmen gliedern
- Kontextwechsel

Leider oft Ursache von Problemen
- Gruppenwechsel

sequentielle Daten nach einer oder mehreren Eigenschaften gruppieren
- Code-Strukturierung

Code so zu organisieren, dass er leicht verständlich, einfach wartbar und nachvollziehbar bleibt
- Copy-and-paste

Warum man Code nicht einfach so übernehmen soll
- DRY (Don't repeat yourself)

Wie man WET (“write everything twice”) vermeidet
- Magic Number

feste Zahlenwerte, die nur in einem bestimmten Kontext das Gewünschte erreichen
- Progressive enhancement
 Zuerst grundsätzliche Funktion, dann Gestaltung und Dynamik
Zuerst grundsätzliche Funktion, dann Gestaltung und Dynamik - Standardverhalten
 Nutze das Verhalten von HTML, statt es zu überschreiben
Nutze das Verhalten von HTML, statt es zu überschreiben
Siehe auch
- Entwicklung wiederverwendbarer Software
Basis-Artikel von Achim Schrepfer
- JavaScript in HTML einbinden

Externe Scripte - Wertübergabe zwischen verschiedenen HTML-Dokumenten

- Buttons mit CSS gestalten

Sauberes CSS ohne Chaos:
Gestaltung mit Variablen und SPOT - Trennung von Inhalt, Präsentation und Verhalten
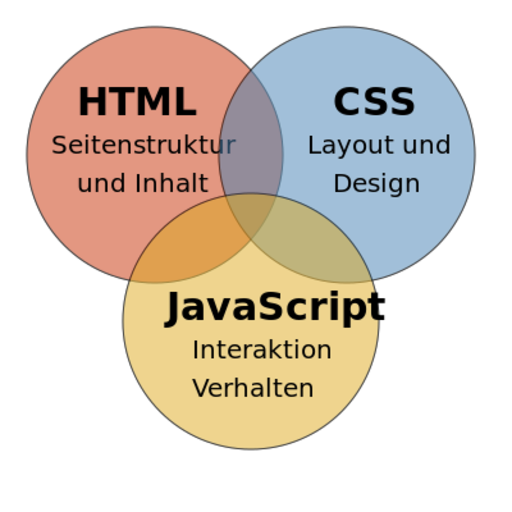
… erklärt, welche Rollen die Techniken HTML, CSS und JavaScript spielen.
Weblinks
- Wikipedia Programmiertechnik

